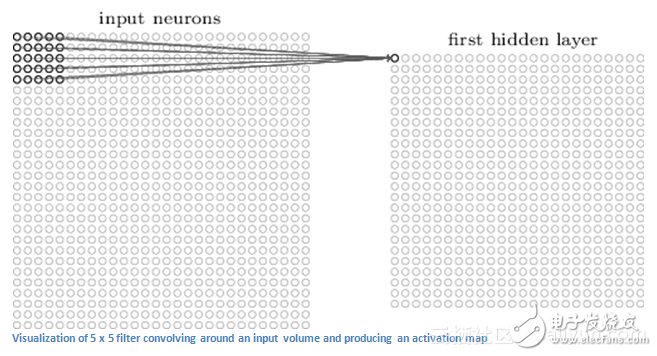
Abstract: What is a convolutional neural network, where does it come from? Where are you going? Follow the rhythm of the author and start exploring CNN together. Convolutional neural networks sound like a strange combination of biology and mathematics, but it is one of the most influential innovations in computer vision. 2012 was the most popular year for convolutional neural networks, because Alex Krizhevsky used it to win the ImageNet competition of the year (basically the computer vision of the annual Olympics), which reduced the classification error record from 26% to 15%. It is amazing improvement. Since then, deep learning has become popular, Facebook uses neural networks for automatic tagging algorithms, Google for photo searches, Amazon's product recommendations, Pinterest for family feed personalization, and search-based Instagram. Today we take a look at how to use CNN for image classification in image processing. Image classification is the task of inputting an image and outputting a class (cat, dog, etc.), or the probability of the class that best describes the image. For humans, this task is one of the first skills we learned from the moment we were born. We humans can quickly and seamlessly identify the environment we are in and the objects around us. When we see an image, or even just look at the world around us, most of the time, we are able to immediately depict the scene and give each object a label, all of which are not aware of the attention. These skills that can quickly identify patterns are inferred from previous knowledge, and adapting to different image environments is our specialty. I personally think this is a unique advantage of the human three-dimensional perspective, compared to the machine's two-dimensional perspective. When the computer sees the image (taking the image as input), it will see an array of pixel values. Depending on the resolution and size of the image, it will see a 32 x 32 x 3 array (3 is the RGB value). Let's assume we have a color image in JPG format with a size of 480 x 480. The representative array will be 480 x 480 x 3. Each of these numbers gives a value from 0 to 255 that describes the pixel intensity at a point. These numbers are meaningless to us when we categorize images, but it is the only input available to the computer. Therefore, this is very difficult in the human subconscious. Now that we know the problem and how to input and output, let us consider how to solve this problem. We want the computer to be able to distinguish all the images and find out the unique features of identifying the dog or recognizing the cat. When we look at a picture of a dog, we can classify the picture if it has recognizable features, such as claws or four legs. In a similar manner, computers can perform image classification by looking for low-level features such as edges and curves, and then constructing more abstract concepts through a series of convolutional layers. This is a general overview of CNN functionality, let's take a closer look. 3.1 Biological Connections First you have to have a little biological background. When you first hear the word "convolution neural network," you might think of something related to neuroscience or biology. CNN does inspire from the visual cortex in biology, which is a cell region that is sensitive to specific regions of the field of view, and the specific regions are generally small. This idea was produced in 1962 by experiments by Hubel and Wiesel. Hubel and Wiesel found that all of these neurons are organized in a columnar structure and together they produce visual perception. The idea of ​​specialized components within a system with a specific task (the neuronal cells in the visual cortex looking for specific features) is also a concept for machine use. It is also a local receptive field that we often say: the area of ​​the initial input image corresponding to the response of a node of the output image. This is also the basis of CNN. Next we talk about the specific details. A more detailed overview of what CNN does will be: taking images, passing a series of convolutions, nonlinearities, pools (downsampling), and fully connected layers, and getting the output. As we said earlier, the output can be a single class or the probability of the class that best describes the image. Now, the hard part is understanding each of these layers, first letting us get to the most important one. 4.1 First layer: Math (Math) Translator's Note: Filter: filter (with a set of fixed weight neurons) convolution calculation of local input data. Now let's take a look at the first position of the filter. When the filter slides or convolves around the input image, it multiplies the value in the filter by the original pixel value of the image (AKA unit multiplication). So you will wait for a number, remember that this number simply represents the filter at the top left of the image. Now let's repeat this process for each location. (The next step is to move the filter 1 unit to the right, then 1 to the right again, and so on.) Each position will produce a number, after the filter will slide all the positions, you will find the rest It is a 28 x 28 x 1 array of numbers, which we call an activation map or a feature map. The reason you get a 28 x 28 array is that there are 784 different positions and a 5 x 5 filter can accommodate 32 x 32 input images. These 784 numbers are mapped to a 28&TImes;28 array. Now we use two 5 x 5 x 3 filters instead of one. Then our output will be 28 x 28 x 2. By using more filters, we can better preserve the spatial dimension.
Auto transfer swtich-ATS panel
. ATS panel
. ATS Switcher: ABB, Socomec, Chint, SmartGen, Askai
. ATS for two Generators
. ATS for Generator and Mains
. 25A-6300A
Auto Start,Ats Panel,Auto Load Transfer,Auto Transfer System, ATS, AMF Guangdong Superwatt Power Equipment Co., Ltd , https://www.swtgenset.com

The first layer in the CNN is always a convolutional layer. The first thing to do is make sure that you remember the input to this transformation. As we mentioned earlier, the input is a 32 x 32 x 3 pixel array. The best way to explain the conversion layer is to imagine a flashlight flashing at the top left of the image. The light from this flashlight covers the 5&TImes;5 area. Now, we can imagine that this flashlight can slide over all areas of the input image. In machine learning terms, such a flashlight is referred to as a filter (or sometimes referred to as a neuron or kernel) and its area of ​​flashing is referred to as the receiving field. This filter is now also an array of numbers (numbers are called weights or parameters). A very important consideration is that the depth of the filter must be the same as the input depth (so that mathematical operations are guaranteed), so the filter size is 5 x 5 x 3.