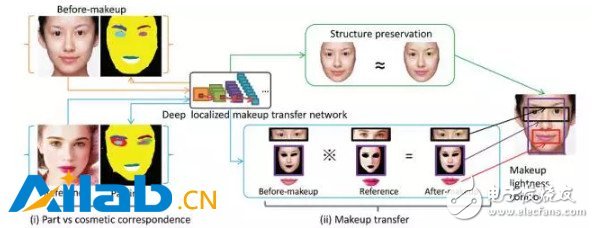
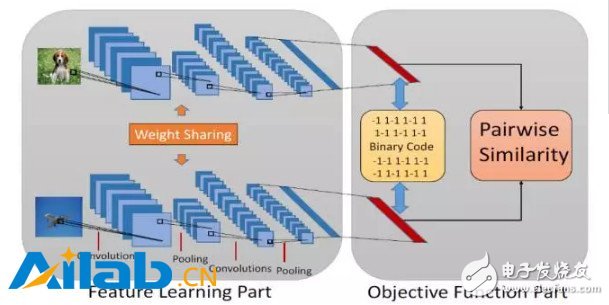
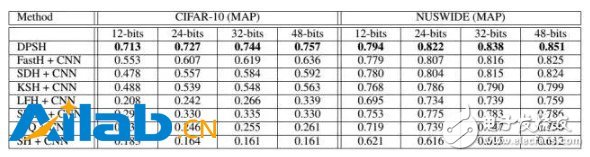
Zhu Pengfei, the author of this article, is an associate professor and master tutor of the machine learning and data mining laboratory of Tianjin University. He received his bachelor's and master's degrees from the School of Energy Science and Engineering at Harbin Institute of Technology in 2009 and 2011 respectively, and his Ph.D. from the Department of Electronic Computing at the Hong Kong Polytechnic University in 2015. At present, he has published more than 20 papers in top international conferences and journals on machine learning and computer vision, including AAAI, IJCAI, ICCV, ECCV, and IEEE TransacTIons on InformaTIon Forensics and Security. The InternaTIonal Joint Conference on Arxificial Intelligence (IJCAI) is a gathering of researchers and practitioners in the field of artificial intelligence and one of the most important academic conferences in the field of artificial intelligence. From 1969 to 2015, the conference was held in each odd-numbered year and has now held 24 sessions. With the continuous warming up of research and application in the field of artificial intelligence in recent years, starting from 2016, the IJCAI Conference will become an annual event held once a year; this year is the first time that the Congress is held in even-numbered years. The 25th IJCAI Conference was held in New York from July 9th to 15th. The venue of this year's conference is near the bustling New York City Times Square, which is lined with the fiery atmosphere of artificial intelligence for several years. The conference included 7 specially invited speeches, 4 award-winning speeches, 551 presentations of peer-reviewed papers, 41 workshops, 37 lectures, and 22 demos. Deep learning has become one of the key words of IJCAI 2016. There are three paper report sessions with the theme of deep learning. In this issue, we selected two related papers in the field of deep learning to select for reading, organized doctoral students in related fields, introduced the main ideas of the paper, and commented on the contribution of the paper. Makeup Like a Superstar Deep Localized Makeup Transfer Network In the application of face segmentation, beauty makeup is a broader issue for the audience. Given a straight face, if you can give it the most appropriate makeup style and render it to this face, it will make it easier for girls to find a suitable style. The problem solved by Dr. Liu et al. of the Chinese Academy of Science and Technology Institute is to complete a fully functional facial automatic makeup application that can not only apply makeup to the makeup but also recommend the most suitable makeup to the user and achieve higher performance. Customer satisfaction. The article adopts an end-to-end method to complete the three steps of style recommendation and facial lifting. At the same time, the smoothness and facial symmetry constraints are also considered in the loss function, and finally achieve the state-of-the-art effect. The overall framework of the method is as follows: The core method: First of all, the style recommendation is to pick the image closest to the current facial makeup face from the makeup database. The specific method is to select the smallest Euclidean distance from the current facial features as a recommendation result, which is the feature map of the network output. Then the facial features are extracted using the full convolutional network to achieve image segmentation to achieve face parsing, but the makeup database has one more part of the eye shadow, for the makeup image there is no eye shadow part of the problem, so according to the features of the facial features Eye shadow area. Since the part of the makeup segmentation is more important than the background, the network output loss is weighted cross-entropy. The weight is the maximum weight value for the F1 score on the verification set. On the other hand, the faces in the database are all positive and symmetric. Therefore, the symmetry a priori constraint is added. The specific method is to output the symmetry of each pixel after outputting the category probability prediction value of each pixel. Click again to take the average as the final output: The last is the makeup transfer. The makeup in this article includes foundation (corresponding to face), lip gloss (for lips), and eye shadow (for eyes). The eye shadow migration is special because it does not directly change the part of the eyes, the article designed a loss for this: It refers to the L2 Norm (this feature is the FCN first layer convolutional feature conv1-1 used in the feature extraction part) for the desired person's face after makeup and the recommended eye makeup with makeup. Similarly, the loss of the face, upper lip and lower lip: The difference is that it calculates the similarity of the features of conv1-1, conv2-1, conv3-1, conv4-1, conv5-1 layers. The last given A that minimizes this loss (that is, the finally given makeup face) satisfies the following conditions: Among them, Rl and Rr indicate the loss of the left eye's right eye shadow, Rf indicates the loss of the face foundation, Rup, Rlow indicates the loss of the upper lip's lower lip gloss, and Rs indicates the loss of the structure (the calculation formula is the same as the eye shadow loss, but Sb, Sr The element value is 1). The smoothness of face makeup can be further constrained by the following formula: In this paper, the end-to-end deep convolutional neural network is used to learn the correspondence between the parts of the makeup behind the makeup, and to perform makeup migration. The process is relatively simple, and it achieves after considering the symmetry and smoothness constraints of the human face structure. The ideal results, some experimental results are as follows: Feature Learning based Deep Supervised Hashing with Pairwise Labels In information retrieval, the hash learning algorithm represents complex data such as images/text/video as a series of compact binary codes (features vectors composed only of 0/1 or ±1), thereby realizing time and space efficient recent Neighbor search. In the hash learning algorithm, given a training set, the goal is to learn a set of mapping functions, so that after the data in the training set is mapped, similar samples are mapped to similar binary codes (similar to binary encoding). Hamming distance measure). In this article by Li Wujun of Nanjing University, the author proposes a method for hash learning using pairwise label. The normal image tag may indicate which category the object in the image belongs to, or what category the scene depicted by the image belongs to, and the pairwise label herein is defined based on a pair of images, indicating whether the pair of images are similar ( It is usually possible to define whether or not they are similar based on whether or not the pair of images belong to the same category. Specifically, for two images i,j in a database, sij=1 means that the two images are similar, and sij=0 means that the two images are not similar. Specific to this article, the author used the network structure shown in the figure above. The input of the network is paired images and the corresponding pairwise label. The network structure contains a two-way subnetwork with shared weights (this structure is called Siamese Network), and each subnetwork processes one of a pair of images. At the back end of the network, based on the binary code and pairwise label of the obtained sample, the author designed a loss function to guide the training of the network. Specifically, ideally, the output of the network front-end should be a binary vector consisting only of ±1. In this case, the inner product of the two-valued code vectors of the two samples is in fact equivalent to the Hamming distance. . Based on this fact, the author proposes the following loss function, hoping to fit the pairwise label (logistic regression) using the similarity (internal product) between sample binary codes: In practice, if you want the front end of the network to output a binary vector consisting only of ±1, you need to insert a quantization operation (such as the sign function) in the network. However, because the quantification function has either zero or no derivative in the definition domain, gradient-based algorithms cannot be used when training the network. Therefore, the author proposes to relax the output of the network front-end and no longer requires the output to be binary. Instead, the network output is constrained by adding a regular term to the loss function: Where U represents the relaxed "binary code" and the remaining definitions are the same as J1. In training, the first item in J2 can be calculated directly from the label of the image pair and Ui, and the second item needs to be quantified by Ui to get the result after bi. After training the network with the above loss function, when the query sample appears, it is only necessary to pass the image through the network and quantify the output of the last fully connected layer to obtain the binary code of the sample. Some of the experimental results in this article are as follows. The method proposed in the article achieves state-of-the-art performance. Even if compared to some non-deep hashing methods that use CNN features as input, there are also significant advantages in performance. : In general, the method proposed in this paper achieves significant performance improvements in image retrieval tasks by jointly learning image features and hash functions. However, because the pairwise label used in this paper is only similar or not similar when describing a pair of samples, it is relatively rough, which inevitably limits the application of this method. In subsequent work, the author may consider using a more flexible form of supervision information to extend the versatility of the method. participants: Hu Lanqing Ph.D. student in the VIPL Research Group, Institute of Computing, Chinese Academy of Sciences Yin Xiaoyi Ph.D. student in VIPL research group, Institute of Computing, Chinese Academy of Sciences Liu Wei Ph.D. student in the VIPL Research Group, Institute of Computing, Chinese Academy of Sciences Liu Wei Ph.D. student in the VIPL Research Group, Institute of Computing, Chinese Academy of Sciences Car Phone Holder,Mobile Holder For Cars,Mobile Phone Holder For Dashboard,Mobile Phone Holder For Car Dashboard Ningbo Luke Automotive Supplies Ltd. , https://www.nbluke.com