Abstract: In order to solve the problem of using a calculator for a special group, a calculator system based on TMS320VC5509 DSP for speech recognition is designed. The core of the calculator system is to use the HMM algorithm to build a speech recognition model. By processing real-time speech signals (digital, arithmetic symbols, etc.), the obtained parameters are matched and identified by the template library parameters, and the calculation module of the TMS320VC5509 DSP is used to realize the addition, subtraction and multiplication of the speech signal within the integer 100. , in addition to computing functions. The experimental results show that the recognition rate of the calculator system in low noise and high noise cases is 94.73% and 76.55% respectively. This article refers to the address: http:// With the rapid development of electronic technology, modern ordinary civil calculators add a lot of complicated operations such as trigonometric functions and power functions, while retaining basic operations such as addition, subtraction, multiplication, and division. However, the basic operation has not changed, still using finger operation, for some special people (disabled people) who need real-time digital calculation or in some special occasions, when the calculator cannot be manually operated, voice recognition is added. It is quite necessary for the module's calculator to perform real-time digital calculations. 1 system hardware design 2 system software design 3 System Test Test the performance of the system at two locations for the characteristics and environment of the calculator. 1) Closed laboratory (location 1), the noise is small, the collected signal is relatively good, and the disadvantage is echo. 2) The classroom (location 2) where the break is between classes, the noise is large, the interference is very strong, and the quality of the signal collection is very poor. 4 Conclusion The speech recognition calculator system designed in this paper can further process the recognized speech signal in addition to the function of speech recognition. Because the HMM model is used for endpoint detection of speech signals, the accuracy of the start and end points of speech signals is greatly improved, and the accuracy of recognition is improved. Due to the complexity of the system operation. Both the amount of calculation and the amount of storage are large, and the voice signal and algorithm need to be processed in real time. The TMS320VC5509 used in the system has the superior performance of 0.05 MW/MIPS and 800 MIPS. Meet real-time recognition. Experiments show that the calculator system has fast processing speed and stable operation, and meets the design requirements.
An Optical Distribution Frame (ODF) is primarily used to connect and schedule optical fibers and optical cables. It is applicable to fiber intersections between an optical transmission network and optical transmission devices as well as between optical cables in an access networks.
ODF with pigtails and adapters contain one ODF, adapters and pigtails. Parts are shipped separately; the installer assembles the pigtails and adapters in the ODF on site. Boxes can be supplied to contain from 6 to 144 fibers. All ODFs are withdrawable and designed for mounting in 19" racks. They are equipped with splice holder and guiding for fibers. We can also supply you with other combinations on request.
Optical Distribution Box,Fiber Optic Distribution Box,ODF Frame,Indoor Frame ODF Chengdu Xinruixin Optical Communication Technology Co.,Ltd , http://www.xrxoptics.com
Keywords: speech recognition; DSP; HMM; calculator; TMS320VC5509
Speech recognition technology is the most natural and simple communication method for human-machine. It is a high-tech technology that allows the machine to automatically recognize and understand the meaning of the speaker and turn the voice signal into the correct text or command. According to the actual application, speech recognition can be divided into: identification of specific people and non-specific people, recognition of isolated words and continuous words, recognition of small and medium vocabulary and infinite vocabulary.
Considering the cost and scope of use, this paper applies a non-specific, isolated word, small vocabulary speech recognition system based on TMS320VC5509 DSP. Through the actual test, the speech recognition system using the DSP has higher real-time and recognition rate. The calculator based on the system has higher accuracy for real-time digital calculation, and can basically solve the problem of using a calculator for special groups and special places. Happening.
1.1 Speech Recognition System The basic principle block diagram of speech recognition is shown in Figure 1. The speech recognition process mainly includes parts such as speech signal pre-processing, feature extraction, and pattern matching. After the voice signal is input, preprocessing and digitization are prerequisites for speech recognition. Feature extraction is an indispensable step in the training and recognition of speech signals. In this paper, the cepstrum parameters of the Mel coefficients of each frame are extracted as the feature values ​​of the speech signal. The template matching algorithm currently has DTW algorithm, HMM hidden Markov model, ANN artificial neural network and so on. In this paper, the HMM hidden Markov model is used, and the extracted feature values ​​are stored in the reference pattern library to match the feature values ​​of the speech signals to be recognized. Matching calculation is the core part of speech recognition. After the feature of the person to be recognized is extracted by the feature, it matches with the template generated during system training. In the speaker recognition, the model corresponding to the model with the highest degree of similarity to the speech to be recognized is taken. Speech as a recognition result. 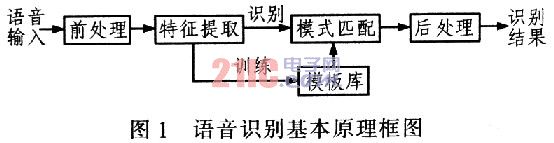
1.2 System Hardware Structure Figure 2 is a block diagram of the system hardware structure. The core device of this system is TI's TMS320VC5509 fixed-point DSP. In this system, it is not only the core of speech recognition, but also the computing part of the calculator. TMS320VC5509 is the system's arithmetic processing unit, with 2 multipliers (MAC), 4 accumulators (ACC); 40-bit, 16-bit arithmetic logic unit (ALU) each, which greatly enhances the computing power of DSP; The word length is not limited to a single 16-bit, it can be expanded to a maximum of 48 bits, and the data word length is 16 bits; the program can be programmed to the TMS320VC5509 via the USB interface without using an emulator. Based on these advantages, choosing this device can save development capital and reduce board area. The interface circuit between DSP and TLV320AIC23 is shown in Figure 3. 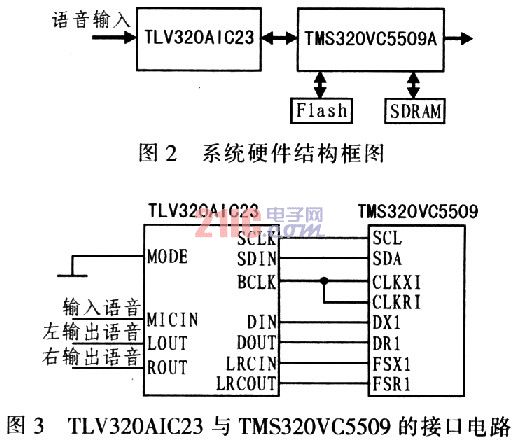
The TLV320AIC23 is a low-cost, low-power audio codec (CODEC) from Tl, which is responsible for acquiring speech signals in this system. Its performance parameters related to this system are: support 8 ~ 96 kHz adjustable sampling rate; adjustable 1 ~ 5dB full cache amplification system. 4 is a circuit diagram of the TLV320AIC23. 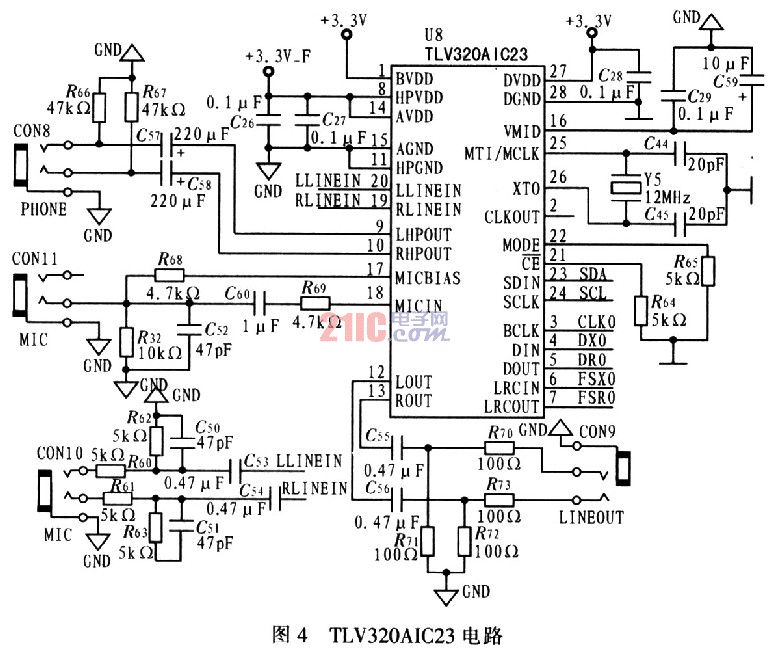
The AM29LV800B memory, also known as flash memory, has on-line rewritable, low power, large capacity, etc., and its storage capacity is 8Mbit. After power-up, the DSP loads and executes the program code from the external Flash, allowing the system to run offline. In this system, it is mainly used to store program code, voice model, and compressed voice data.
HY57V641620 Synchronous Dynamic Memory (SDRAM) with a capacity of 4 M × 16 bit. As an extension of RAM, it greatly enhances the storage and computing power of the DSP. Used to load an acoustic model placed in Flash when the system is initialized. In this way, in the process of speech recognition, the acoustic model can be accessed through the off-chip SDRAM, which is faster than directly accessing the Flash to obtain the acoustic model data. The LCD display is used to display the speech-recognized numbers and operands in real time, and display the answers after getting the prompt to display the final result.
2.1 System Software Flow Figure 5 shows the software flow of the system. After the entire system starts running, initialize the DSP and TLV320AIC23 so that the initial values ​​of the respective registers meet the requirements. After the system acquires the speech signal through the TLV320AIC23, it must first perform pre-filtering and pre-emphasis; then divide the speech signal into frames; then calculate the short-term energy and short-term average zero-crossing rate of each frame signal to provide the next threshold decision. According to the threshold decision, after the endpoint detection, the Mel cepstrum parameter (MFCC) of each frame is extracted as the feature value of the frame signal; finally, the feature value of the processed speech signal is matched with the template, this part is the system. the key of. The speech signal corresponding to the template lock with the largest similarity is the recognition result. The numbers and operands are displayed on the display based on the results of the recognition, and the results are obtained and displayed by the arithmetic rules. 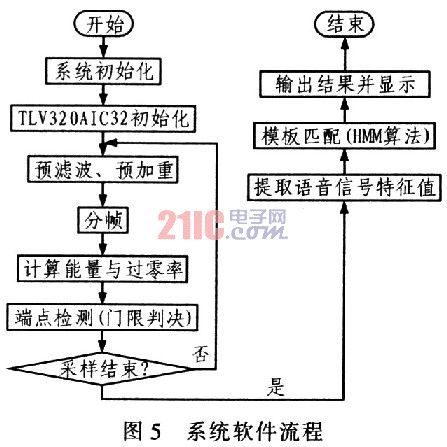
2.2 Pre-processing Pre-processing is the sampling of speech signals, A/D conversion, pre-filtering and pre-emphasis, framing, etc. A voice analog signal acquired at a sampling frequency of 8 kHz and 16 bits. The system uses a bandpass filter for filtering with an upper cutoff frequency of 3.4 kHz. The lower cutoff frequency is 60 Hz. Since the speech signal has a strong correlation, the problem of frame repetition should be considered when framing. In this paper, the speech signal is 256 samples as one frame, and the number of repetition points between the two is 80. The acquired signal is processed by a first-order filter H(z)=1-a/z.
Endpoint detection is the detection of the beginning and end of the speech of an isolated word from the speaker's voice command. Endpoint detection is an important part of the speech recognition process. Only when the isolated words are separated from the background noise of the speaker can the speech recognition work be further carried out. This article uses short-term energy and zero-crossing rates to detect endpoints. The short-term energy analysis of the speech signal gives a suitable description of the magnitude of the response.
The short-term zero-crossing rate, that is, the number of times the signal passes zero value in each frame, can reflect the spectral characteristics of the signal to some extent. The short-term average zero-crossing rate in a frame of speech signal is defined as: 
Using the short-term energy parameter to detect the end point, the short-term energy of the signal {x(n)} is defined as: 
Where {x(n)} is the input signal sequence.
After the start of the formal endpoint detection, the short-term energy and the short-term zero-crossing rate are used as thresholds to determine the start and end of the speaker command word; the continuous five-frame speech signal exceeds the threshold as the start of the speaker command word, for 8 consecutive frames. The speech signal below the threshold is considered to be the end of the speaker command word.
2.3 Feature Value Extraction The Mel Cepstrum Parameter (MFCC) of each frame is extracted as the feature value of the frame signal. The cepstrum feature is one of the most effective features for speaker personality traits and speaker recognition, which is based on the human ear model. The extraction process is as follows:
1) The original speech signal S(n) is subjected to pre-emphasis, windowing, etc. to obtain a time domain signal x(n) of each speech frame. The discrete spectrum X(k) is then obtained after discrete Fourier transform (DFT). 
Where N represents the number of points of the Fourier transform.
2) The discrete spectrum X(k) is passed through M Mel frequency filter banks to obtain the Mel spectrum and processed by logarithmic energy to obtain a logarithmic spectrum S(n). Calculate S(n) through the output of each filter to obtain M h(m) parameters. 
3) Perform logarithmic operation on all filter outputs, and further perform discrete cosine transform (DCT) to obtain MFCC parameters. 
Generally in the choice of Mel filter. The Mel filter bank selects the filter of the triangle, but it can also be other shapes, such as a sinusoidal filter bank.
2.4 Template matching (HMM algorithm)
In this paper, the hidden Markov model (HMM algorithm) is used for pattern matching. It uses the feature vector as a template. When the speech recognition mode is matched, the input speech is compared with the template in the template library, and finally the highest similarity is taken as the output result. The HMM algorithm solves the distortion problem caused by the speaker's different speech rate and continuous speech, and can greatly reduce the calculation time and improve the recognition rate.
Hidden Markov Model is a statistical model of a double stochastic process. The basic stochastic process is hidden and cannot be observed. Another stochastic process produces an observation sequence. For the speech recognition system, the observation sequence 0 is the result sequence of the vector quantization, and the model λ is the template obtained from the training speech. The training process of speech is the process of generating template λ, and the process of speech recognition is to find the conditional probability P[O/λ] of the result sequence 0 of the speech to be recognized under the template λ.
The definition of α(i) and β(i) can be directly obtained: P[O/λ]=αt(i)βt(i). The speech training algorithm is more complicated. At present, the iterative method is used to obtain the approximate solutions of a and b. The iterative formula is as follows: ![]()
In practical applications, a speech recognition system that trains only a few pronunciations of a term. It is impossible to have a high recognition rate for different pronunciations in various complex contexts. Some older recognition algorithms, such as dynamic time warping, can only form multiple training words into multiple templates, resulting in a multiplication of the number of templates, affecting the real-time nature of the system. The HMM can effectively fuse multiple training sequences of a word to form a template. When the number of training pronunciations increases, it only causes an increase in the amount of calculation of the training process. Without an increase in the amount of calculation of the recognition process, this is quite advantageous for the real-time performance of the system.
Because the design of the whole system is to realize the calculation function of the calculator, this experiment is to display the mathematical operation formula on the display after the system recognizes the voices such as numbers and arithmetic symbols, and recognizes “equal to†or “get†2 The speech of the phrase shows "=" and the final calculation result.
Pre-acquisition of 5 males and 5 females with a total of 1 000 voice samples before the test (contents are numbers 0 to 100, plus, minus, multiply, divide, equal and ten, hundred, thousand, ten thousand and other basic calculations required for numbers and arithmetic symbols Pronunciation) and train all samples. In addition, 10 people (4 females, 6 males) were tested in real time at each experimental site, 10 per person, for a total of 100 untrained samples. The system was tested with these samples, and the test results are shown in Table 1. 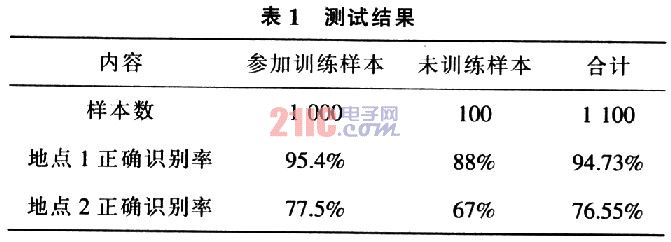
As shown in Table 1, under the same experimental equipment conditions, the system recognition rate in a less noisy environment is much higher than in a noisy environment. In particular, the recognition rate of untrained samples in noisy environments is relatively low, mainly because the noise in the environment is quite complicated. Looking at the spectrogram, the noise is almost superimposed with the speaker's speech, and the algorithm is difficult to identify.